Proposed System
System Overview
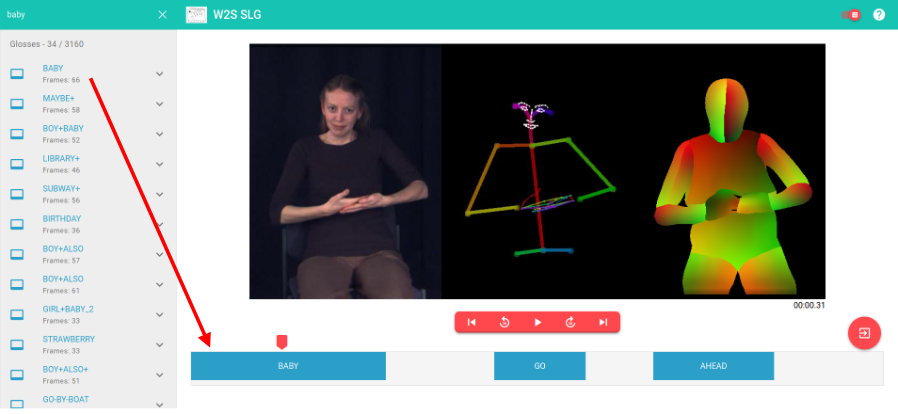
Web Graphical User Interface
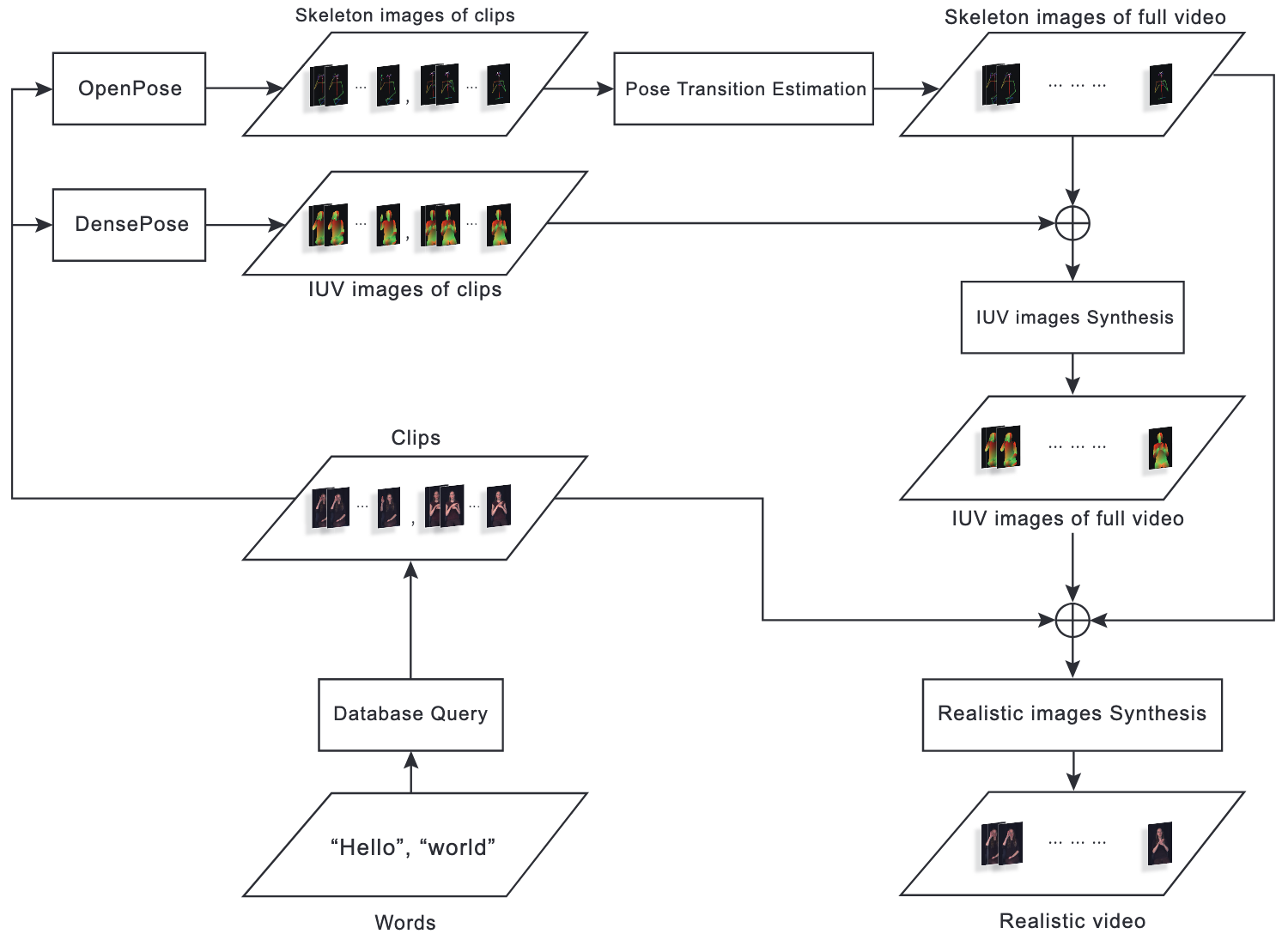
There are many ways to generate sign language videos, but most of them are based on 3D character modeling. These methods are time-consuming and labor-intensive, and are hard to compare with the videos of real person sign language in terms of realness and naturalness. To address this, we propose a novel approach using the recently popular generative adversarial network to synthesize sentence-level videos from word-level videos. A pose transition estimation is used to measure the distance between sign language clips and synthesize the corresponding transition skeletons. In particular, we propose an interpolation approach, as it is faster than a graphics approach and does not require additional datasets. In addition, we also propose an stacked based approach for the Vid2Vid model. Two Vid2Vid models are stacked together to generate videos via two stages. The first stage is to generate IUV images (3 channels images composed by the index I and the UV texture coordinates) from the skeleton images, and the second stage is to generate realistic video from the skeleton images and the IUV images. We use American Sign Language Lexicon Video Dataset (ASLLVD) in our experiment, and we found that when the skeletons are generated by our proposed pose transition estimation method, the quality of the video is better than that of the direct generation using only the skeletons. Finally, we also develop a graphical user interface that allows users to drag and drop the clips to the video track and generate a realistic sign language video.

We presented a text-to-sign language realistic video generation system that can synthesize sentence-level videos from word-level clips. This is achieved by our stacked models scheme which consists of skeleton images to IUV image synthesis and skeleton image & IUV image to realistic image synthesis. The proposed system has addressed the problem of single-hand and two-hands motion transition as faced in Yulia et al.’s work and addressed the consistency of styles like dress color, hair style or even background color. And we proposed an algorithm to prevent different style images being generated through models by constraining the input data (i.e. skeleton correction). We found that generating a full video makes better style consistency than the concatenation of real clips and the generation of transition clips, because part associations estimated by OpenPose sometimes may fail when two hands are crossed or when one of the hands is blurry. The pattern is also learned by the models, and therefore, we apply skeleton correction before synthesizing a video. The skeleton images to IUV images synthesis could be considered successful if we use human eyes to assess the quality, but evaluation metrics show that the quality is not very high, compared with other realistic synthesis approaches. We found that the length of the knuckles can be used to determine whether the pose of a hand is irregular or abnormal. And we proposed a method for correcting irregular hand poses.